
A Machine Learning-Based Approach to Climate Predictability Studies
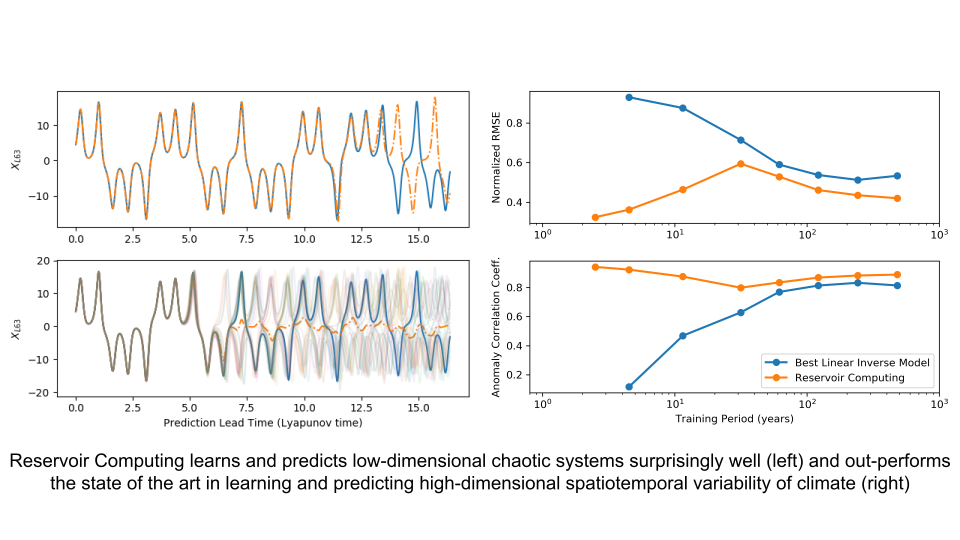
Understanding to what degree different aspects of the climate system---both in terms of natural variability and in terms of response to external-forcing---are predictable is a foundational aspect of climate science. However, a model-centric approach to predictability can be problematic in that the apportioning of sources of predictability for a quantity of interest (QoI) can be so different across models as to make it difficult to relate such studies to the actual climate system. A complementary data-centric approach that is capable of leveraging both model data and observations is pursued. A nonlinear approach based on reservoir computing, a form of machine learning (ML) that is suited for learning dynamics of chaotic systems, is shown to be a useful tool for climate predictability studies that improve on the state-of-the-art Linear Inverse Modeling (LIM) approach.
- The proposed data-driven, ML-based approach to predictability, by leveraging both model data and observations, has the potential to better characterize the predictability of the actual climate system than a purely model-centric approach.
- State-of-the-art climate models are less skillful at predicting natural variability (initialized predictions) than they are at modeling the response of the climate system to external-forcing. The new data-driven methodology will potentially provide more skillful predictions of natural variability (near term initialized predictions) than state-of-the-art climate models
Comprehensive climate models have emerged as a useful tool to disentangle and better understand the myriad processes underlying climate. However, such models are invariably biased because of the difficulty in accurately representing and reproducing the delicate dynamical balance of processes that underlies both the mean state and the modes of variability of the observed climate system. Furthermore, since predictability is state-dependent, such model bias undermines efforts to understand predictability, particularly, of natural variability to the extent that it is sometimes difficult to relate perfect-model predictability studies to the actual climate system.
Data-driven models, where data may come from either models or observations, have a useful role to play in this setting. For example, model bias prevents comprehensive climate models from producing skillful near-term “initialized predictions”; data-driven models can potentially be more skillful at such predictions. From an understanding perspective, such data-driven models permit the testing and comparison of dynamical mechanisms across models and in observational data. In ongoing work we are investigating the use of statistical learning, machine learning, and deep learning in improving data-driven models. In this article, we focus on one such technique called reservoir computing. Its surprising skill in predicting trajectories of low-dimensional chaotic systems is a subject of active research. In the (high dimensional) setting of learning spatio-temporal variability of sea surface temperature in the North Atlantic in the CESM2 piControl experiment, the new methodology performs slightly better than LIMs when learning data is plentiful and much better when such data is limited.